Linux /dev/urandom and concurrency
Recently I was surprised to find out that a process that I expected to to complete in about 8 hours was still running after 20. Everything appeared to be operating normally. The load on the server was what we expected, IO was minimal, and the external services it was using were responding with latencies that were normal.
After tracing one of the sub-processes we noticed that reads from
/dev/urandom were not what we expected. It was taking 80-200ms to read 4k from
this device. At first I thought that this was an issue with entropy but
/dev/urandom is non-blocking so that probably wasn’t the issue.
I didn’t think that 80-200ms was typical so I tried a dd on the system
in question and another similar system in production. The system in question
took about 3 minutes to write 10Mb while the reference system took about 3s.
The only difference between the systems with respect to /dev/urandom was the
rate and number of processes reading from the device. The reads were on
the order of hundreds per second.
The number of processes reading from /dev/urandom made me wonder if maybe
there was a spinlock in the kernel in the read code. After looking at the code
I found one. You can see the spinlock here
in the Linux kernel source code. The author mentions the potential for
contention in a thread
on the mailing list from December 2004.
Fast forward 10 years and contention on this device is a real issue. Our
application uses curl from within PHP to fetch data from a
cache. The application has to process 10s of
millions of text objects and we don’t want to wait days for that processing
to complete so we split the work of processing each object over N threads.
The read from /dev/urandom appears to be coming from
ares_init
which is being called from curl_easy_init in our version of PHP+curl. Removing
the AsynchDNS feature from curl causes the problem to go away
(tracing confirms that the read from /dev/urandom is no longer there). You can
remove this feature by compiling with --disable-ares.
So why is this an issue? I wrote a python script
to measure the read times from /dev/urandom as you increase the contention by
adding more threads. Here is a plot with the results.
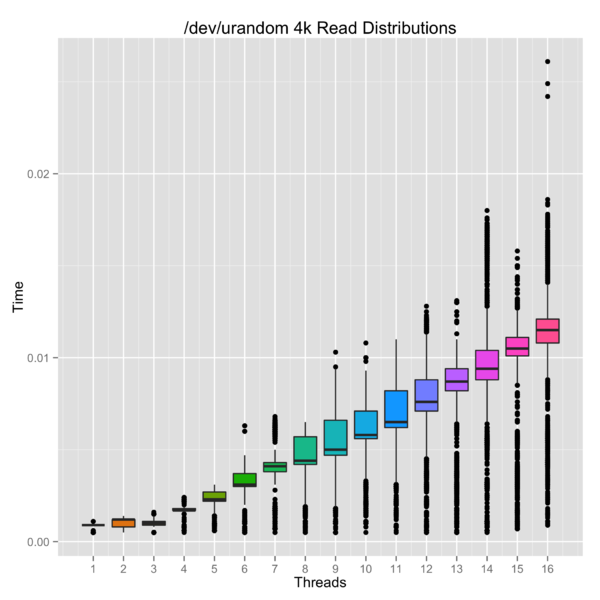
Running the same script with a user-land file is more or less linear out to 16 threads. A simple spinlock can have a big impact in the multi-core world of 2014!